
Advancing Nursing Excellence Through Evidence-Based Practice, Leadership, Informatics, and Lifelong Learning
Other |
2026-06-20 16:53:53
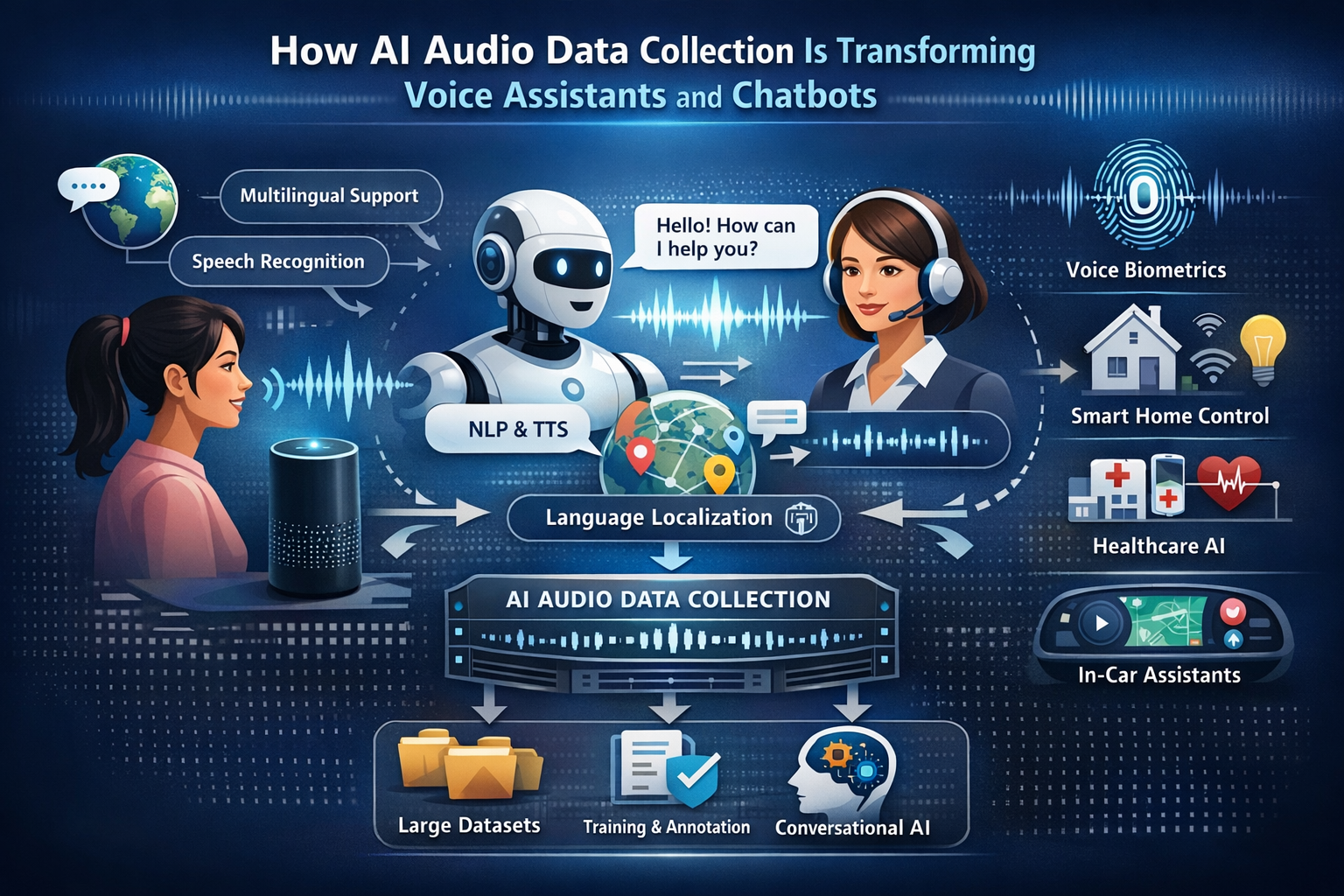
In a world where businesses are expanding beyond borders, language is no longer just a communication tool it is a growth factor. Yet, it remains one of the biggest barriers to global scalability. This is where AI audio data collection plays a transformative role, especially in building multilingual AI systems that can understand, process, and respond in multiple languages.
In 2026, multilingual AI is not optional it is essential. With billions of users interacting through voice-enabled systems, companies must ensure their AI can understand diverse accents, dialects, and languages. High-quality AI audio data collection is the foundation that makes this possible.
The demand for multilingual AI is driven by global user behavior and market expansion.
Over 80% of customers prefer interacting in their native language, directly impacting conversions and user satisfaction
AI speech recognition systems now support 100+ languages with up to 90–95% accuracy
More than 61% of businesses plan to adopt multilingual AI within the next 2 years
These numbers highlight a clear shift: businesses that fail to adapt to multilingual AI risk losing global opportunities.
“Language is no longer a barrier for users but it can still be a barrier for businesses that lack the right data.”
AI audio data collection refers to gathering voice data across multiple languages, accents, and environments to train AI systems.
For multilingual AI, this includes:
Native speech recordings in different languages
Accent and dialect variations
Code-switching conversations (mixing languages)
Real-world audio environments
The goal is to train AI systems to understand language in context, not just translate words.
AI models rely heavily on training data. AI audio data collection ensures that systems can:
Recognize different languages seamlessly
Adapt to pronunciation variations
Reduce speech recognition errors
Modern voice AI systems can achieve up to 85%+ enterprise-level accuracy when trained with high-quality datasets
Supports Code-Switching and Real Conversations
In many regions, especially India and Southeast Asia, users switch between languages in a single sentence.
AI audio data collection helps models learn:
Mixed-language conversations
Contextual language switching
Natural speech flow
Without such datasets, AI systems fail to understand real-world communication patterns.
Improves Global User Experience
Multilingual AI powered by strong AI audio data collection can:
Deliver personalized interactions
Improve customer satisfaction
Increase engagement and retention
“Speaking the user’s language is no longer a feature—it is an expectation.”
Companies are now collecting audio data in dozens of languages simultaneously. Modern platforms offer 75+ language support with thousands of voice variations
Focus on Real-World Data
Instead of relying only on synthetic datasets, businesses are prioritizing:
Real conversations
Background noise environments
Natural speech patterns
This improves model performance in real-life situations.
AI-Assisted Annotation
Annotation has become more advanced, including:
Language identification
Intent recognition
Emotion tagging
This helps AI systems understand context, not just words.
Growth of Voice-First Ecosystems
Over 2.2 billion people globally use voice search
Voice assistants are expected to exceed 10 billion devices worldwide
This growth is pushing businesses to invest more in AI audio data collection.
Despite its importance, building multilingual datasets is complex.
AI systems often struggle with regional accents and pronunciation differences
Many languages lack sufficient training data, affecting accuracy.
Handling mixed-language conversations remains a technical challenge.
Voice data must be collected ethically and securely.
“Building multilingual AI is not just about adding languages—it’s about understanding human communication in all its diversity.”
To build effective multilingual AI systems, businesses should:
Collect diverse and representative audio datasets
Include regional accents and dialects
Invest in high-quality annotation
Continuously update datasets with real-world inputs
Partner with experts for scalable solutions
These steps ensure better performance, scalability, and global reach.
AI audio data collection is the driving force behind multilingual AI in 2026. It enables systems to understand languages, accents, and real-world conversations, breaking barriers that once limited global communication.
As businesses expand internationally, investing in high-quality multilingual datasets is no longer optional it is essential for success.
“The future of AI is multilingual and it is powered by data that truly understands the world.”
Why is AI audio data collection important for multilingual AI?
It provides the diverse datasets needed to train AI systems to understand multiple languages, accents, and real-world speech patterns.
How does multilingual AI improve business growth?
It allows businesses to connect with global audiences, improve customer experience, and increase conversion rates.
What challenges exist in multilingual AI audio data collection?
Challenges include accent variability, data scarcity for certain languages, and handling code-switching.
How can businesses get started with multilingual AI?
By collecting high-quality audio data, using advanced annotation, and partnering with experienced providers.



